
(文/陈兴华)一句话生成一段高清视频,OpenAI再次给业内带来震撼。在OpenAI发布的近50多个Sora演示视频中,包含细节拉满的场景、复杂的摄像机以及多个充满情感的角色。
据OpenAI官网公布的Sora大模型技术报告显示,Sora的核心技术主要包括Diffusion Transformer架构和时空patches。而在缔造这一惊世产品背后,Sora团队成立却不足1年,而且核心成员仅十余人,包括研发主管是应届博士,以及00后和华人成员。
相比传统文生模型,Sora的突出优势体现在“大片质感”、“时长感人”以及“匹配自如”等。但需要看到,Sora作为生成式AI模型的一颗“新星”并不算完美,仍存在一些不成熟之处,比如逻辑性还有待提升,以及在更精细内容的调控方面有待加强。
无论如何,Sora的出现已经给业界带来了较充分的想象空间,包括被视为将给众多行业带来颠覆式变革。然而,不容忽视的是,Sora的诞生也意味着中美两国的AI大模型竞争差距可能还在加大。对此,国内产业界还需在诸多方面下足功夫、加速追赶。
核心团队仅十余人
在Sora模型的震撼业界同时,其幕后主创团队也引发关注。
据OpenAI在官网发布的技术报告介绍,Sora创作者团队仅十余人,其中Tim Brooks、Bill Peebles是研发主管,Connor Holmes是系统主管。据了解,Tim Brooks与Bill Peebles师出同门,都曾于2019年8月进入伯克利深造,受Alyosha Efros教授指导。2023年上半年,两人一前一后在伯克利获得博士学位,并相继加入OpenAI。
Sora作者 图源:OpenAI官网
在此之前,Tim Brooks本科就读于卡内基梅隆大学,主修逻辑与计算,曾在Meta软件工程部门实习,并在谷歌工作近两年,从事Pixel手机部门中的AI相机研究工作。而Bill Peebles本科毕业于麻省理工学院(MIT),主修电脑科学、辅修计算机科学,曾参加GAN 和text2video的研究,以及在Adobe和英伟达深度学习与自动驾驶团队实习。
另外,Connor Holmes毕业于科罗拉多矿业大学,电气电子工程学士、高性能计算博士,曾一直在微软从事研究员工作,2023年12月加入OpenAI,参与Sora、DALL·E等项目。
除了应届博士管理层,Sora的团队成员中甚至不乏“00后”Will DePu。资料显示,Will DePu于2003年出生于华盛顿州西雅图市,毕业于加州大学洛杉矶分校格芬学院,曾在高中就参与多个项目研发,并创立了自己的公司。同时,Sora的团队也有不少老兵坐镇,包括David Schnurr、Joe Taylor、Aditya Ramesh、Eric Luhman等均有较丰富行业经验。
值得关注的是,Sora核心名单中还有三名华人研究者。
据悉,Li Jing是DALL-E 3的共同作者,2014年毕业于北京大学物理系,2019年获MIT物理学博士学位,后在Meta工作两年,2022年加入OpenAI从事研究工作,包括多模态学习和生成模型。Ricky Wang毕业于加州大学伯克利分校,此前在Meta和ins任职软件工程师及工程经理,今年1月从Meta跳槽至OpenAI。虽然Yufei Guo尚未有太多公开资料介绍,不过OpenAI两大“王炸”项目——GPT-4和Sora中都有他的名字。
从团队组建情况和研究基础来看,Sora的核心团队是一支非常年轻的队伍,而且开发Sora模型的时间并不长。纽约大学助理教授谢赛宁日前在社交媒体上表示,Sora是Bill Peebles等人在OpenAI的呕心之作。“Bill告诉我,他们每天基本不睡觉高强度工作了一年。”
此外,根据Sora技术报告的参考文献,来自谷歌、Meta、MIT等产业界和学术界的技术人员也都作出了重要贡献。可见Sora是顶级人才汇聚和高强度研发等综合的结果,正如谢赛宁所言,“对于Sora这样的复杂系统,人才第一,数据第二,算力第三,其他都没有什么不可替代。”
被拒收论文成就“王炸”
在Sora技术报告引述的32篇论文中,第26篇(即“Scalable diffusion models with transformers”)被视为最重要的一篇,其作者正是Bill Peebles和谢赛宁。尽管谢赛宁称Sora团队与自己没有关系,但其与Bill Peebles曾经的研究为Sora的实现奠定了基础。
图灵奖得主、Meta首席AI科学家杨立昆称,他的前同事谢赛宁和他在伯克利的学生Bill Peebles前年合著的关于DiT的论文是Sora的重要基础之一,Sora基本上是基于这篇被ICCV(国际计算机视觉大会)2023收录的论文提出的框架设计而成。
然而,这篇论文曾因为“缺乏创新”被CVPR(国际计算机视觉与模式识别会议)2023拒绝。对于被拒收的论文为何成就了新“王炸”,上海交通大学人工智能研究院副教授王韫博认为,这与OpenAI的工程能力密不可分。在公开发布的技术信息中,OpenAI也坦言,Sora使用了大规模训练和超大数据集,但并没有透露训练规模和参数细节。
谢赛宁推测,整个Sora模型可能有30亿个参数。如果这一推测合理,可能表明训练Sora模型不需要像人们预期的使用那么多的GPU算力,而且预计未来大模型的迭代会非常快。他还表示,“Bill和我在DiT项目上工作时,我们没有创造新奇事物,而是优先考虑两个方面:简单性和可扩展性。这些优先事项提供的不仅仅是概念上的优势。”

Sora生成视频图片 图源:OpenAI官网
“简单性意味着灵活性。Sora可以通过在适当大小的网格中排列随机初始化的块来控制生成视频的大小。而可扩展性是DiT论文的核心主题。首先,优化后的DiT在每Flop的墙钟时间上运行得比UNet快得多。更重要的是,Sora证明了DiT的扩展规律不仅适用于图像,现在也适用于视频——Sora复制了在DiT中观察到的视觉扩展行为。”他说。
据了解,Sora的重大突破就在于其所使用的DiT架构。此前,传统的文生视频模型通常是扩散模型(Diffusion Model),GPT-4等文本模型则是Transformer模型,而Sora则通过采用DiT架构融合了两者的特性。此外,Sora的另一项关键技术是Spacetime Patch(时空Patch),该技术的论文是由Google DeepMind的科学家于2023年7月发表。
在技术原理方面,OpenAI公布的Sora大模型技术报告显示,基于Diffusion Transformer,从一开始看似静态噪声的视频出发,经过多步骤的噪声去除过程逐渐生成视频。而时空patches将不同类型的视觉数据转化为统一的表现形式。同时,该模型对语言有着深刻的理解,能够准确地演绎提示内容,并生成情感表达充分且引人注目的角色。
“碾压”同行但并不完美
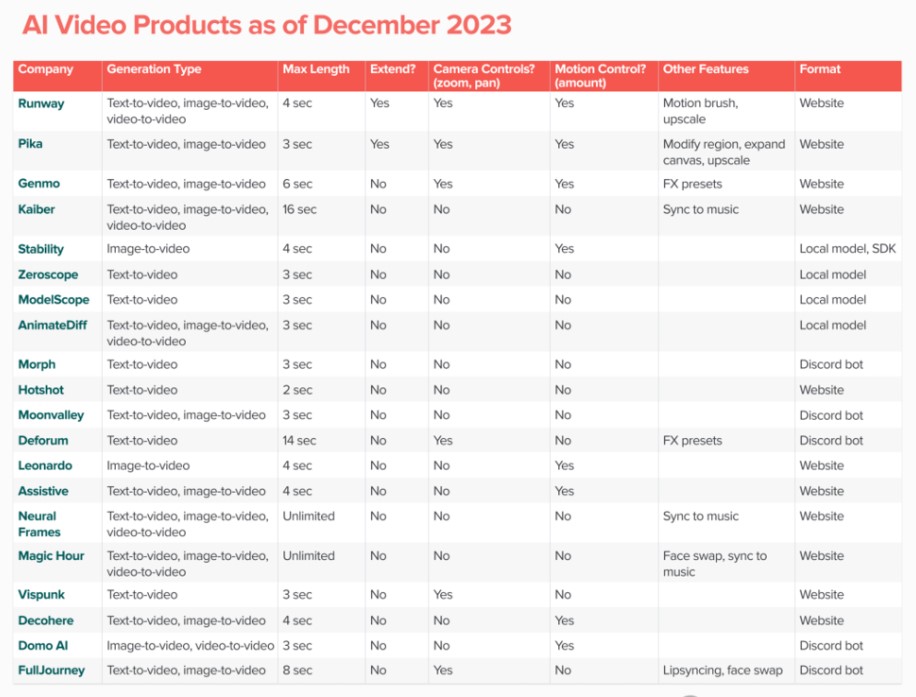
事实上,文生视频并非新鲜事物。在Sora发布前,知名投资机构a16z便已追踪统计了大型科技企业和初创公司发布的21个公开AI视频模型(截至2023年底),其中包括较为业界熟知的Runway、Pika、Genmo以及Stable Video Diffusion等。
那么,Sora凭什么在还没有正式开放的情况下就掀起了业界震撼?
国信计算机认为,首先,Sora可生成60秒超长视频。相较于Runway、Pika等文生视频大模型(生成时长基本均在10秒以内),Sora可以生成60秒一镜到底的视频。其次,多角度视频一致性。Sora可以在单个生成视频中创建多个镜头,以准确保留角色和视觉风格。另外,尝试理解物理世界。根据OpenAI官网披露,Sore不仅可以理解用户Prompt的要求,同时亦尝试理解Prompt中的事物在物理世界中的存在方式(即物理规律)。
相比之下,传统文生视频即便是几秒钟的视频也并不连贯,不仅有较强拼凑感,在视频质量、分辨率、高宽比和稳定性等方面还也存在较明显不足。而Sora所展现出的技术能力,几乎可以用“碾压”来形容,从而使得其生成的视频demo色彩艳丽、效果逼真。
在多位行业人士看来,Sora的尤为“惊艳”之处体现在其对物理世界的理解和模拟能力,包括其带有“世界模型”的特质,这让其在逼真度上更胜一筹。所谓“世界模型”便是对真实的物理世界进行建模,让机器能够像人类一样,对世界产生一个全面而准确的认知。
OpenAI显然也展示出了打造“世界模型”的雄心,例如其在官网发布的Sora技术报告就取名为“Video generation models as world simulators(视频生成模型成为世界模拟器)”。然而,对于Sora是否能真实理解物理世界,业界还存在不同的观点。
作为“世界模型”概念的主要倡导者,杨立昆指出,仅仅根据提示词(prompt)生成逼真视频并不能代表一个模型理解了物理世界,生成视频的过程与基于世界模型的因果预测完全不同,“这其中存在‘巨大’的误导。”此外,要让AI模型领悟前后两帧画面之间的逻辑关联也非常困难,需要从大量数据中去学习和掌握生成语言、图像或视频的某种方法。

Sora生成视频图片 图源:OpenAI官网
进一步来看,虽然Sora的技术令人惊艳,但视频生成能力并不完美。根据已披露的视频显示,不少素材仍会“一眼假”,不符合物理学规律等AI生成的Bug(漏洞)不少,例如在呈现“红酒杯在桌上摔碎”的镜头中,杯子摔碎前红酒已洒满桌子,违背了物理逻辑。同时,与文本对话和图片生成相比,训练成本高昂、高质量数据集的缺乏、视频描述的模糊性和复杂度以及知识产权合规或输出内容不侵权等,都将是Sora需要跨越的门槛及挑战。
或许正是考虑到性能、安全和技术实现等问题,Sora尚未向公众开放,目前处于安全测试阶段。据预测,预计Sora将于8月向公众开放,届时Sora可能将得到进一步完善升级。
中企有待加速追赶
无论如何,Sora的横空出世已经引爆了学界、业界和投资界的讨论热度。
在国内,中信建投、国泰君安、申万宏源、招商证券等10多家券商在研报中均表示,Sora是人工智能发展进程的里程碑,预示AGI(通用人工智能)将加速到来,众多行业将迎来颠覆式变革。业内人士指出,Sora会推动上游AI服务器、AI芯片、还有光通信行业发展以及云厂商基础设施建设。此外,影视、广告营销、游戏、IP等内容行业都有可能会受益。
然而,在Sora震撼亮相同时,其它国内外的大模型企业也开始了新一轮的竞逐,而随着从文本、图像再到视频模型的差距进一步拉大,“追赶”又成了新一轮的主题。面对OpenAI的竞争,Pika创始人郭文景回应:“我们已经在筹备直接冲,将直接对标Sora。”
据了解,国内国外的文生视频领域呈现出不同的竞争态势。

Sora生成视频图片 图源:OpenAI官网
在国外,文生视频领域已经形成了“科技巨头+创业派+专业派”,虽然目前文生视频模型产品以创业公司推出为主,但科技巨头基本都已入局,只是产品尚未公测,同时一些轻量化的垂直细分工具企业也在涌现。相比之下,国内企业也在加码文生视频领域,如百度的UniVG,腾讯的VideoCrafter2,阿里的Animate Anyone以及字节跳动的MagicVideo-V2等,但目前的产业路线、竞争格局和业态还尚不清晰,以及投入力度并不充分等。
有分析称,中国学术界或产业界有能力实现文生图,在此基础上可以产生秒级(10秒以内) 视频,但难以做到视频前后语义一致性,或只能局限于特定场景,这与之前的国际前沿水平差不多,但与Sora相比差距甚大,这是大语言模型和多模态大模型上差距的直接映射。
诚然,尽管国内大模型近年来取得显著进展,但与OpenAI、谷歌、英伟达等国际大公司相比,仍存在技术差距。360董事长周鸿祎表示,国内大模型发展水平表面看已经接近GPT-3.5,但实际上跟4.0比还有一年半的差距。OpenAl手里应该还藏着一些秘密武器,无论是GPT-5,还是机器自我学习自动产生内容以及AIGC… 这样看来中国跟美国的AI差距可能还在加大。
对于Sora为什么没出现在中国,谢赛宁认为,假设真的出现了(可能很快),但我们有没有准备好?如何能保证知识和创意的通畅准确传播,让每个人拥有讲述和传播自己故事的“超能力”,做到某种意义上的信息平权,但是又不被恶意利用。而OpenAI有一整套的red teaming(红队),safety guardrail(安全护栏)的研究部署,欧美也有逐渐成熟的监管体系。
显然,Sora在为国内产业界带来震撼同时,也再次敲响了“警钟”。面对这一重要课题,国内企业要迎头赶上,势必还需要在技术研发、应用创新、人才培养、市场拓展和共建合作等多方面下足功夫,毕竟人工智能竞争事关未来科技发展和产业变革的绝对高地及主阵地。
(校对/张轶群)








