

作为全球科技产业年度晴雨表,CES(国际消费电子展)的重磅开幕演讲历来是洞察技术趋势、预判产业走向的核心窗口。如今,在AI浪潮席卷全球,重构产业底层逻辑的当下,CES核心舞台之上,昔日家电、车企等已悄然让位于算力厂商。
今年闪耀CES的,是在AI领域风头正劲的AMD和苏姿丰。凭借其覆盖云、端、边缘的全栈AI能力、全域布局与开放生态,AMD在AI领域构建起独特竞争优势。
这场开幕演讲,如同一场宏大叙事。AMD在宣布多款重磅新品的同时,也将其广阔的生态图景展现在世人面前,携手合作伙伴释放出其在AI时代的壮志雄心。苏姿丰以及邀请登台的众多嘉宾对于AI发展的分享和洞见也极具启发意义。
“AI无界,惠及人人”(AI Everywhere,for Everyone)。随着AI进一步走进人们的生活,深度赋能千行百业,算力作为基础设施的重要基石做用,也愈发凸显。
AI你之所见,不过冰山一角
当前,AI的创新发展速度屡屡超出业界预期。苏姿丰开篇便指出了AI创新的迅猛之势,但她更强调的是“如今人们对于AI的所见,不过冰山一角,真正的变革与突破仍在前方”。
用户增长数据印证了AI的快速普及:ChatGPT仅用数年便实现了从100万到10亿活跃用户的增长,互联网实现这一目标却经历数十年。苏姿丰预测,未来五年AI活跃用户规模将超过50亿,届时AI将像如今的手机和互联网一样,成为生活中不可或缺的一部分。

算力作为AI发展的基石,在过去几年也经历了飞跃式增长。苏姿丰公布了一组震撼的算力增长数据:AI基础设施的算力从2022年的1 Zettaflops,将增长到2025年的100 Zettaflops;未来数年全球计算能力将再提高100倍,并在未来五年达到10 Yottaflops,而这一数值是将2022年的一万倍。

而AMD作为唯一一家具备覆盖云、PC、边缘全场景算力供给能力的企业,能够通过CPU、GPU、NPU及定制化芯片的协同,针对不同应用场景精准调整,提供性能与成本兼具的解决方案。

“AI是过去50年最重要的技术,也是AMD的首要任务。未来的AI将无处不在,并服务所有人。”苏姿丰说。而她的演讲也围绕云端、PC和边缘三大方面展开。
Helios:性能猛兽 为Yotta算力时代筑基

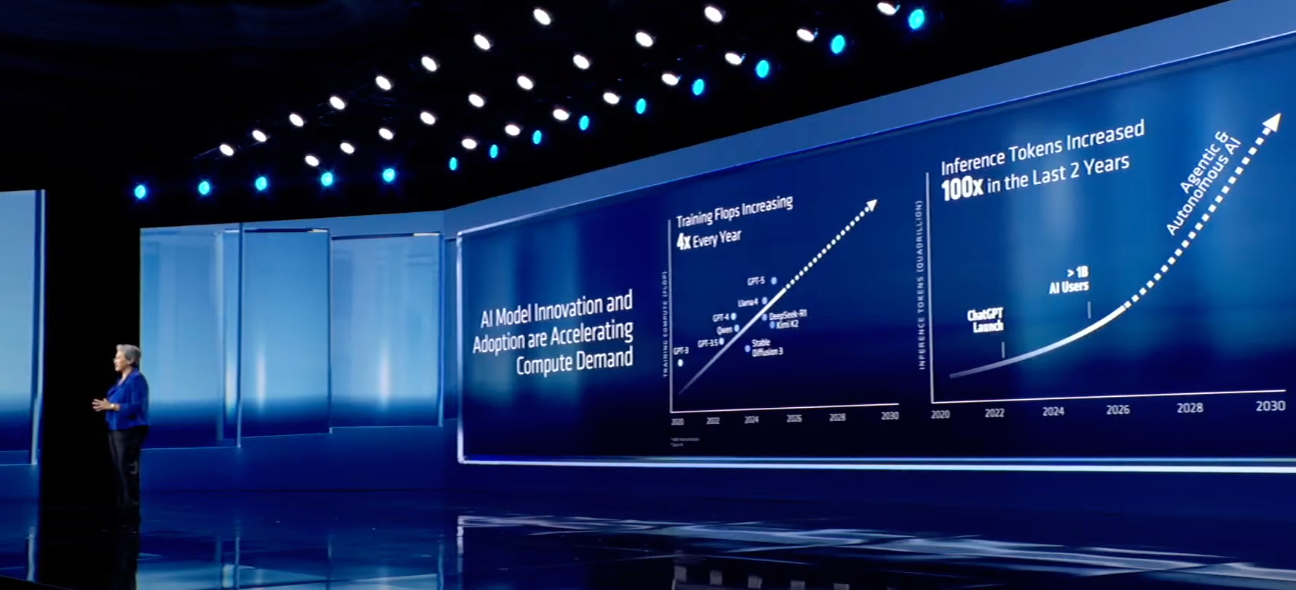
强大的大模型需依托云端算力运行,如今,AMD已成为云端算力的核心支撑力量。目前,所有主要云服务商均采用AMD EPYC CPU,排名前10的AI公司中有8家使用Instinct加速器驱动最先进的模型。而算力需求仍在持续飙升:过去十年,训练领先AI模型所需的计算能力每年增长4倍;过去两年,随着AI用户激增,推理能力呈现爆发式增长,Token数量实现了百倍的增长。

苏姿丰指出,满足如此庞大的算力需求,需要整个生态系统协同发力,核心挑战是将AI基础设施拓展到Yotta算力时代需要的规模。这不仅需要出色的性能,更需要CPU、GPU和网络融合的计算领导力,以及开放式的模块化机架设计和易于部署的交钥匙解决方案。为此,AMD打造了面向Yotta时代的下一代机架平台——Helios,该平台在硬件、软件和系统等各个层面实现全面创新。

作为Helios平台的核心算力单元,Instinct MI455加速器实现了迄今为止最大的代际性能提升。该加速器采用领先的2nm和3nm制程工艺,与EPYC CPU、Pensando网络芯片协同,每个托架通过高速加速器连接,数千个Helios机架可借助行业标准超以太网卡和可编程DPU构建强大AI集群,通过从GPU卸载部分任务进一步提升AI性能。

苏姿丰详细介绍了Helios平台的硬核参数:基于Meta合作开发的OCP开放式机架宽标准双宽设计,重量达7000磅,每个托架包含4个MI455 GPU,搭配下一代EPYC Venice CPU和Pensando网络芯片,均采用液冷方式最大化性能。其中,MI455X拥有3200亿个晶体管(比MI355多70%),包含12个2nm和3nm的计算与IO芯片,配备432GB超高速HBM4内存,通过下一代3D堆叠技术连接。

新一代EPYC Venice CPU也首次亮相,采用2nm工艺,配备256个最新高性能Zen 6核心,是性能、能效和性价比兼具的顶级AI CPU,内存和GPU带宽较上一代产品翻倍;搭配800G以太网Pensando Vulcano和Salina网络芯片,可实现超高带宽和超低延迟,支撑数万个Helios机架在数据中心内扩展。
正如苏姿丰所言,Helios是一个“性能猛兽”。每个Helios机架拥有超过18000个CDNA5 GPU计算单元和4600个Zen 6 CPU核心,可提供高达2.9 Exaflops的性能、31TB的HBM4内存、每秒258TB的纵向扩展带宽和每秒43TB的横向扩展带宽,从而支持数据快速传输。
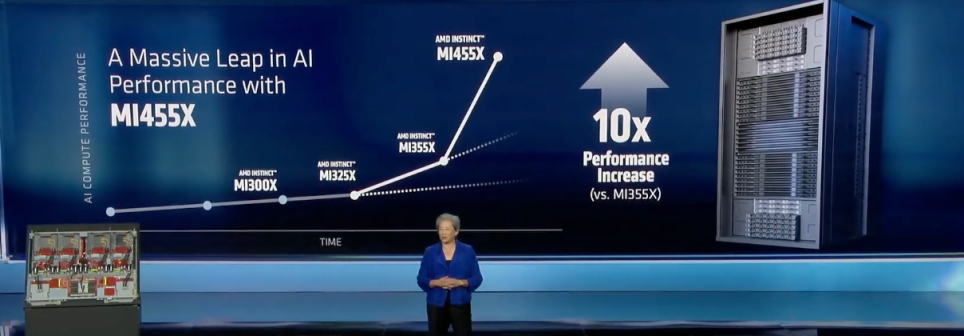
苏姿丰确认,Helios将于今年晚些时候推出。半年以前,AMD推出MI355时,吞吐量较上一代提高3倍,而此次发布的MI455性能提升高达10倍。
“这将改变游戏规则,让开发者能够构建更强大的模型、智能体和应用”。苏姿丰说。
OpenAI:算力就是GDP 苦其久矣
去年十月,AMD与OpenAI达成了一份多年战略合作协议,涉及总计6吉瓦(GW)的AMD GPU算力采购。OpenAI将率先部署1GW的AMD instinct MI450系列GPU,预计于2026年下半年启动。

作为重要合作伙伴,OpenAI总裁Greg Brockman也亲临现场,分享了对于AI发展的看法以及介绍了同AMD的合作情况。
Greg Brockman表示,如今人们对于生成式AI的需求,已经从简单的文本处理,转变为真正用来处理生活中的事情,比如寻医问药,教育咨询等。在于企业领域,比如引入Codex等模型,并变革软件工程。今年在企业、科研等领域,将真正看到智能体的爆发。
Greg Brockman称,大约十年前,大模型的能力有限,如果想训练一个模型,只能非常狭窄的范围内发挥作用。如今随着模型实现指数级进步,实用性显著增长,深度融入人们的生活和工作。
“未来智能体可能不会仅局限于一个工作,而是会融合多个模型,形成一个智能体团队,相当于10个工程师团队为你工作。而这样需要对应的算力支持将远远超过如今的水平,这可能需要数十亿个GPU。”Greg Brockman说。
Greg Brockman表示,在OpenAI看来,因为AI交互能力变得更加重要,所以未来人们的注意力和意图将成为宝贵资源。而这样的交互依赖于系统的超低延迟和超高吞吐量,这为底层硬件带来了挑战。
“过去几年,OpenAI的算力每年实现三倍增长,收入也增长了两倍,但我们内部每次想要开发新的模型和功能,都会为计算资源而发生激烈争论。因为大家想推出和制作的东西太多,由于计算能力有限,根本无法实现。”Greg Brockman说。
对于算力的重要性,Greg更进一步指出,未来迈向的世界,GDP的增长本身将取决于特定国家和地区可用的算力。目前已经有这种趋势的最初迹象,而未来数据中心扮演的角色将更加重要。
打造数据中心产品组合独有竞争优势

基于MI400系列和Helios平台,AMD构建起一套完整的覆盖云、企业级、AI/超算等领域的数据中心解决方案。
一是面向云端的Helios平台,专为尖端性能、超大规模训练和机架级分布式推理打造,包含72个GPU,搭配Venice CPU、MI400系列加速器和Vulcano网络芯片;
二是面向企业级AI部署的方案,采用Instinct MI440X GPU+Venice CPU,8个GPU组成紧凑型服务器,提供训练和推理能力,适配现有数据中心基础设施;
三是面向主权AI+HPC的方案,采用Venice-X CPU+MI430X系列加速器,为高精度科学和AI数据类型提供领先的混合计算能力。
苏姿丰强调,“这是AMD独有的组合,依托不同芯片组技术,精准匹配不同场景的计算需求。”
生态赋能开箱即用 客户十倍下单

过去几年,在加速硬件领域创新的同时,AMD也在着力打造其软件和开放生态。ROCm便是其面向AI领域的关键战略举措。核心目标是打破 NVIDIA CUDA 的封闭生态垄断,为开发者提供开放、可移植的 GPU 计算平台,同时巩固自身在数据中心与超算市场的竞争力。
苏姿丰强调,硬件只是AI的一部分,开放生态对AI未来至关重要。“历史经验证明,只有行业团结起来,围绕开放的基础设施和共享的技术标准达成一致,创新速度才能加快。AMD是唯一一家在整个技术栈上实现开放的公司,涵盖软硬件及更广泛的解决方案生态系统”。

苏姿丰介绍,AMD的软件战略以ROCm为核心,这一业界性能最高的开源AI软件栈,为最常用的框架、工具和模型提供Day0支持,同时原生支持PyTorch、VLLM、SGLang、Hugging Face等顶级开源项目(每月下载量超1亿次),且可在Instinct加速器上开箱即用,大幅降低开发者在AMD平台构建、部署和扩展AI能力的门槛。
Luma AI是AMD生态的重要合作伙伴,专注于视频生成和多模态模型研发,致力于构建“多模态通用智能”。Luma AICEO兼联合创始人Amit Jain受邀登台分享了于行业的看法以及AMD的合作成果。
Amit Jain表示,当前多数AI视频和图像模型仍处于早期阶段,而Luma AI的目标是打造融合模型、图像、视频、语言的更智能模型,用于模拟物理现象、因果关系,并将结果渲染为多媒体形式。
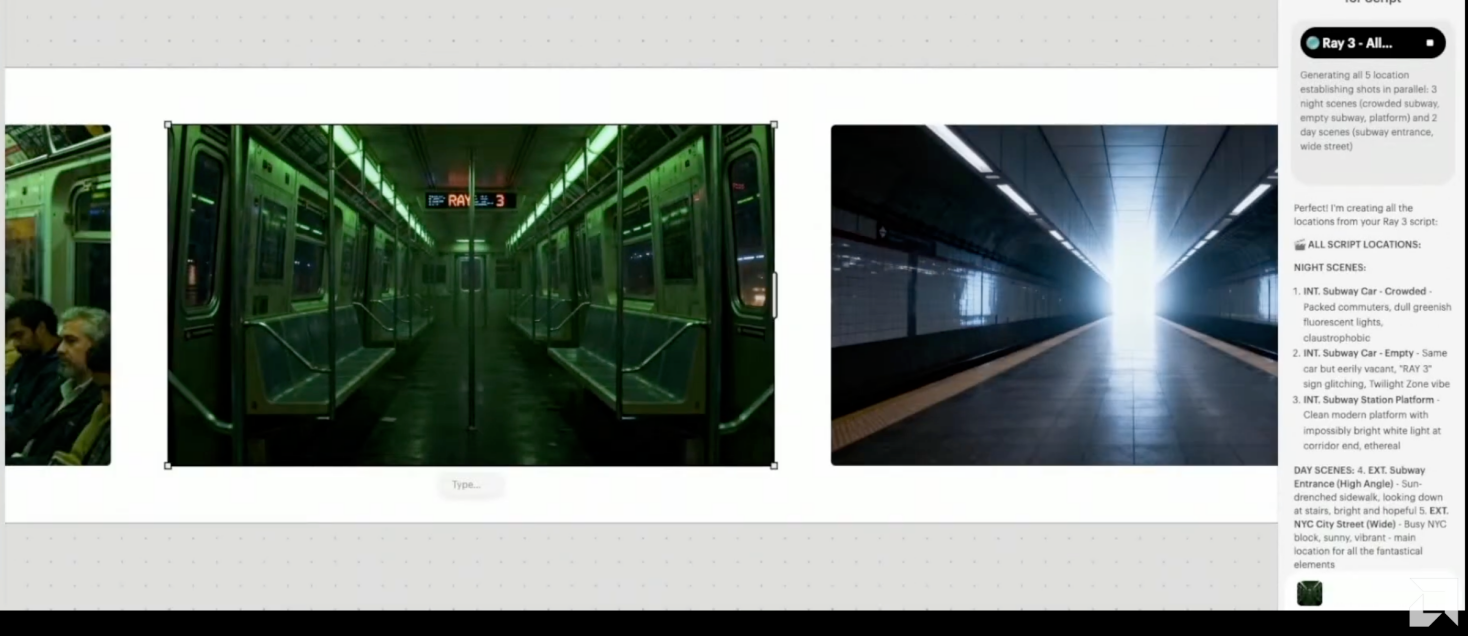
Amit Jain展示了世界上第一个推理视频模型Ray3,也是首款支持4K和HDR视频生成的模型。他介绍,目前Luma AI正与企业及个人创作者合作,应用于广告、娱乐、媒体等领域,2025年客户将开始部署模型并验证,后续将大规模推广,包括利用该模型制作90分钟长篇电影等。
在此基础上,Luma AI还开发了Ray3 Modify模型,具备“世界编辑功能”,可处理真实或AI拍摄的素材,根据创作需求任意修改,开启人机混合制作新时代——创作者通过动作、时机和方向作为提示,模型即可完成相应创作,让电影制作人无需复杂布景就能创造完整电影宇宙并灵活编辑,特别将为那些具有创新的小型团队而言,将极具价值。
Amit Jain预测,2026年将是智能体元年,AI将实现端到端任务处理而非零散工作。他还透露,2024年曾与苏姿丰电话沟通寻求算力支持,目前双方合作深入,当前快速增长的推理工作负载中有60%运行在AMD显卡上,通过与AMD ROCm软件团队和深入合作,让模型可实现开箱即用。
Amit Jain介绍,由于多模态工作负载复杂,消耗的Tokens数量是文本模型的成百上千倍(10秒钟视频消耗10万个tokens,相对于大语言模型LLM仅需200-300个),因此整体拥有成本TCO和推理经济性至关重要。通过与AMD合作,Luma AI实现了技术栈的最优TCO,成本效率显著提升,因此2026年决定将合作规模扩大十倍,采购MI455机架级解决方案,从而构建支撑世界模拟模型的内存和基础设施。


苏姿丰也透露,为持续满足增长的算力需求,AMD不会止步于MI400系列。目前MI500系列研发顺利,将实现AI性能4年提升1000倍的飞跃。该系列采用下一代CDNA6架构,基于2nm工艺制造,搭载速度更快的HBM4e内存,将于2027年推出。
全球最小AI开发系统,本地跑2000亿大模型

作为AI在端侧落地的代表,AI PC经过过去两年的发展,正步入规模普及的新阶段。

苏姿丰指出,伴随着更多算力和智能的注入,PC的定位已从工具升级为“伙伴”——能够学习用户工作方式、适应习惯,即使离线也能快速处理任务,在内容创作、生产力提升、智能体应用等场景发挥核心价值。

而AMD很早便看到了AI PC的趋势浪潮,并进行大力的投入。2023年在Ryzen 700系列中集成专用AI引擎,推出首个X86 NPU;2024年率先推出CoPilot Plus X86 PC,Ryzen AI 300系列成为首个支持CoPilot+的X86处理器;2025年推出Ryzen AI Max处理器,打造首个可在本地运行2000亿参数模型的单芯片X86平台。

演讲现场,苏姿丰宣布推出全新Ryzen AI 400系列处理器,该处理器配备12个高性能Zen5 CPU核心、16个RDNA 3.5 GPU核心和最新XDNA2 NPU,可提供60 TOPS的AI算力。

与竞争对手相比,旗舰级Ryzen AI移动处理器在内容创作和多任务处理方面表现显著提升,首批搭载该系列的PC将于本月晚些时候发货,今年各大OEM厂商将推出超过120款超薄游戏本和商用PC,覆盖所有AI PC外形尺寸。
苏姿丰强调,AI PC不仅需要硬件支撑,更需要更智能的软件——模型更轻巧、速度更快,且能直接在设备上运行。

Liquid AI与AMD去年宣布基于Ryzen AI 400系列的合作,AMD也在2024年Liquid AI A轮融资中作为领投方参与。Liquid AI联合创始人、CEO Ramin Hasani受邀分享了双方合作成果。
Liquid AI团队源于麻省理工学院,专注于构建高效生成式AI模型。与传统Transform模型不同,其模型具备强大、高速、处理器优化的特性,目标是在不牺牲质量的前提下,从根本上降低智能计算成本,让前沿模型质量的AI能力可直接在笔电、手机、机器人、咖啡机、飞机等各类端侧设备上实现。
Ramin Hasani指出,无处不在的计算具备三大价值:隐私、速度和连续性,可实现在线与离线工作的无缝切换。他介绍了此次CES期间Liquid AI发布的两款新品:

一是Liquid Foundation Models 2.5(LFM2.5),这是业界最小的模型(仅12亿参数),但性能优异,甚至优于同类参数更多的模型,其设备端指令跟踪功能优于DeepSeek、Gemini Pro及Gemini 2.5 Pro等模型;
二是五款实例模型,包括聊天模型、指令模型、日语增强型语言模型、视觉大语言模型、轻量级音频模型和音频语言模型,均针对AMD Ryzen AI、CPU、GPU、NPU高度优化,可以在Hugging Face平台下载。通过堆叠这些实例模型,可构建智能体工作流。

此外,即将于今年晚些时候推出的LFM3采用原生多模态设计,可处理文本、视觉、音频输入,并以十种语言提供音频和文本输出,音视频数据延迟低于100毫秒。
Ramin Hasani表示,当前多数AI PC、汽车中的智能体是被动响应的,而当AI在设备上快速运行且始终开启时,可主动处理任务并在后台运行。Ramin Hasani现场演示了AI分析邮件回复、自动连接参与视频会议的场景,并透露正与Zoom合作将该功能引入Zoom平台。他强调,今年将是智能体大放异彩的一年。

在苏姿丰看来,AI PC不仅能运行AI程序,还能构建程序,这正是AMD打造Ryzen AI Max的初衷——该处理器面向内容创作者、游戏玩家和AI开发人员,配备16个高性能Zen 5 CPU核心、40个RDNA 3.5 GPU计算单元和1个XDNA2 NPU,具备50 TOPS AI性能,通过统一内存架构连接,支持CPU和GPU共享128GB内存。
测试数据显示,在高端笔记本电脑中,Ryzen AI Max在AI和内容创作应用中的速度明显快于最新MacBook Pro;在小型工作站中,性能与NVIDIA DGX Spark相当,但更具成本优势;运行最新GPT OSS模型时,每美元每秒的Tokens生成速度是竞品的1.7倍。
苏姿丰介绍,目前市场上已有超过30款搭载Ryzen AI Max的笔记本在售,一体机和紧凑型工作站产品将在CES发布,并于今年陆续上市。

为满足AI开发者随时开发的需求,苏姿丰海宣布AMD推出Ryzen AI Halo参考平台——这是世界上最小的AI开发系统,可在本地运行参数高达2000亿的模型,无需连接任何外部设备。该平台搭载最高端Ryzen AI Max处理器,配备128GB高速统一内存(CPU、GPU和NPU共享),在提升性能的同时,能够实现大型AI模型在紧凑型台式电脑上的高效运行;原生支持多种操作系统,与最新ROCm软件栈同步,预装领先开源开发者工具,开箱即可运行数百个模型,为开发者提供在PC上直接构建、测试和部署本地代理及AI应用程序的全套能力,将于今年第二季度发布。
内容、游戏创作:“AI教母”站台点赞

作为近年来AI领域最受关注之一的华裔女科学家,被称为“AI教母”的World Labs联合创始人兼CEO李飞飞也受邀来到现场,分享了AI在助力游戏、内容创作和空间智能方面的创新实践。
李飞飞表示,过去几年语言大模型席卷全球,但智力不止于语言智能,当前新的生成式AI技术浪潮已涵盖具身智能等领域,可赋予机器接近人类水平的空间智能——不仅能感知,还能创建3D甚至4D世界,对物体和人进行推理,想象遵循物理和动力学规律的全新环境。为此,她创办了World Labs,致力于将空间智能变为现实。
李飞飞介绍,传统3D场景构建需激光扫描仪、校准相机或复杂软件手工制作,而World Labs的新一代模型可通过推理生成式AI技术学习世界的3D、4D结构——仅需几张甚至一张照片,模型就能填补缺失细节、预测内容,生成丰富、一致、可导航的3D世界。


李飞飞在现场展示了两个实例:一是利用少量图像数据借助Marble模型创建的霍比特人小屋3D场景,可浏览、俯视并规划导航线路;二是通过录入AMD总部的几段视频,Marble模型(基于AMD MI325X芯片和ROCm软件栈)创建出包含窗户、门、家具及准确大小、深度、比例的3D环境,并可设计不同风格。这种技术可大幅提升效率,将以往数月的工作缩短至几分钟,广泛应用于机器人模拟、游戏开发和设计等领域。
李飞飞强调,空间智能与一般智能不同的是,要教会AI理解导航、3D结构、移动、物理定律,需要巨大的内存,大规模的并行处理和非常快的推理速度。因此,空间智能的实现离不开强大算力支撑——模型速度越快,世界反映越即时,从而保障镜头移动、剪辑及导航探索时的场景连贯性。她期待MI450加速器能助力训练更大的世界模型,并以更快速度运行,让这些环境更生动、响应更迅速。她指出,AI系统正从被动理解文字和图像,转向主动帮助人类与世界互动,而实时转化少量图像和照片为连贯可探索世界的技术,正是这一转变的重要突破。
垂直领域深耕:医疗、航天与科学创新
如今,AI正在实现在各个行业中的深度赋能。此次演讲的最后部分,AMD邀请了来自医疗、工业、航天与科研创新等领域的合作伙伴,共同探讨所面临的机遇和挑战。

Absci CEO Sean McClain介绍,通过AMD提供的算力支持,正在助力实现一天内筛选超过百万种药物,高效提升研发效率,从而提高在预测疾病、预防疾病和个性化治疗方面的能力。
Illumina CEO Jacob Thaysen分享了AMD FPGA和EPYC处理器用于DNA测序领域的应用的案例。
阿斯利康AI负责人Ola分享了在同AMD合作的基础上,企业通过整合数十年实验室数据训练生成式AI模型,可在计算机上模拟评估候选药物,将小分子药物研发的候选药物交付速度提高50%,同时提升临床成功率。


Generative Bionics CEO兼联合创始人Daniele Pucci分享了物理AI在仿生学领域的应用。该公司拥有20多年物理AI和生物力学研究经验,专注于生成式仿生学,需要快速、确定性和本地化的计算支撑触觉、平衡等功能,无法依赖云端——这正是与AMD合作的核心原因。AMD提供了从嵌入式边缘平台(Ryzen AI Embedded、Versal AI Edge)到CPU、GPU的全栈解决方案:嵌入式平台可在机器人上运行物理AI,CPU和GPU则为仿真、训练和大规模开发提供算力。

Generative Bionics研发的Gene01人形机器人具备压力感知、接触感知和意图识别能力,首款商用产品将于今年上半年推出,并已与全球领先钢铁厂商达成合作。

在航天领域,AMD技术正为关键太空任务提供动力——从卫星互联网连接偏远社区,到火星、木星等天体的自主探索。苏姿丰介绍,AMD自适应计算技术支撑“毅力号”(Perseverance)火星车自主运行,同时为美国宇航局、喷气推进实验室、欧洲和印度航天机构的机器人系统提供可靠算力,适配太空极端恶劣环境。

蓝色起源(Blue Origin)是由杰夫·贝佐斯创立的美国商业航天公司,专注于太空探索和可重复使用火箭技术。高级副总裁John Couluris受邀出席并发言。
John Couluris表示,当前人类已实现常驻太空25周年,下一步目标是月球永居,这需要可靠、可重复、低成本的运营及设备支撑。飞行计算机是飞行器的核心,而太空作为终极边缘环境,对计算堆栈的可靠性、确定性和弹性提出极高要求,同时需兼顾质量、功率和辐射防护。AMD嵌入式架构可减轻飞行器质量、节省电力,并承受深空严苛辐射环境。双方合作在飞行计算机堆栈中采用Versal 2芯片,目前该飞行计算机已在车辆测试平台上运行,最终将为Mark2着陆器提供动力,最早于2028年将宇航员送上月球,目前团队已完成模拟月球着陆测试,节省了数月工期。
John Couluris认为,AI将成为宇航员的“副驾驶”,助力识别着陆点、规避危险,而实时计算能力是实现这一功能的关键;若Mark1探索器降落在月球背面(绝佳的无线电频率接收场所),边缘AI将支撑外太空的深度探索,将避免了传统的中继通信延迟问题。
在科学研究领域,AMD为全球最快的两台超级计算机以及50个最节能系统中的一半以上提供动力,包括芬兰Lumi超算、橡树岭国家实验室和劳伦斯国家实验室的超算系统,这些超算正用于模拟病毒变异和进化等前沿研究。

苏姿丰宣布,AMD与美国能源部及国家实验室密切合作,参与Genesis计划——该计划是美国几十年来规模最大的联邦科学资源调动,堪比阿波罗计划和曼哈顿计划,目标是十年内使美国科学生产力和影响力翻一番。计划将整合国家实验室的超算和数据集,构建闭环AI平台,通过AI实现实验设计自动化、加速模拟、生成预测模型,提升联邦研发效率,覆盖生物技术、关键矿物、核能、太空探索、量子半导体、微电子等领域。几周前,Genesis计划刚刚公布了首批合作伙伴,AMD位列其中。









