
1月19日至22日,第31届亚洲及南太平洋设计自动化会议(Asia and South Pacific Design Automation Conference, ASP-DAC 2026)在中国香港举办。我院缪向水、李祎教授团队在本次大会发表了两项关于存算一体领域的最新研究成果。其中,关于Transformer混合存算加速器的研究工作荣获大会最佳论文提名奖(Best Paper Award Nomination)。这是对我院在存算一体与AI硬件加速领域科研实力的重要肯定。
ASP-DAC会议是集成电路设计自动化(EDA)领域全球著名会议之一,也是亚洲及南太平洋地区在此领域最具影响力的国际学术盛会,由IEEE和ACM联合主办。会议致力于展示在集成电路设计、嵌入式系统设计及电子设计自动化等方面的最新研究成果。本届会议竞争激烈,共收到639篇投稿,最终录用176篇,其中仅有14篇文章被提名为最佳论文。
成果一:Transformer混合存算加速器(获最佳论文提名)
论文题目:“OAH-CIM: Outlier-Aware Hybrid RRAM-SRAM CIM Accelerator with Variation-Robust Sparsity”,集成电路学院博士生周志威为第一作者。

图1 周志威演讲照片
Transformer已成为当前AI领域的主流模型,但其庞大的参数量和计算复杂度给硬件部署带来了巨大挑战。传统的冯·诺依曼架构面临严峻的“存储墙”瓶颈,而存算一体技术(CIM)通过在存储器内部进行计算,极大地减少了数据搬运,被视为打破这一瓶颈、实现高效Transformer推理的关键技术路径。然而,在实际设计中,单一存储介质往往面临“两难境地”:RRAM(阻变存储器)密度高适合存储巨大的静态权重,但其耐久性低难以应对频繁更新的动态激活;SRAM(静态随机存取存储器)读写速度快,适合处理注意力机制中频繁更新的动态矩阵,但密度低难以容纳静态权重。为此,RRAM-SRAM混合异构架构成为当前的理想架构。
Transformer激活值中广泛存在的长尾离群值,迫使传统量化方案为保全大数而牺牲绝大多数小数值的精度,导致信号本身极其脆弱 。此时,若直接采用传统的比特稀疏策略来加速计算,会导致计算周期内的电流负载剧烈波动——高密度的电流脉冲会显著放大RRAM器件的模拟变异噪声。(图2)
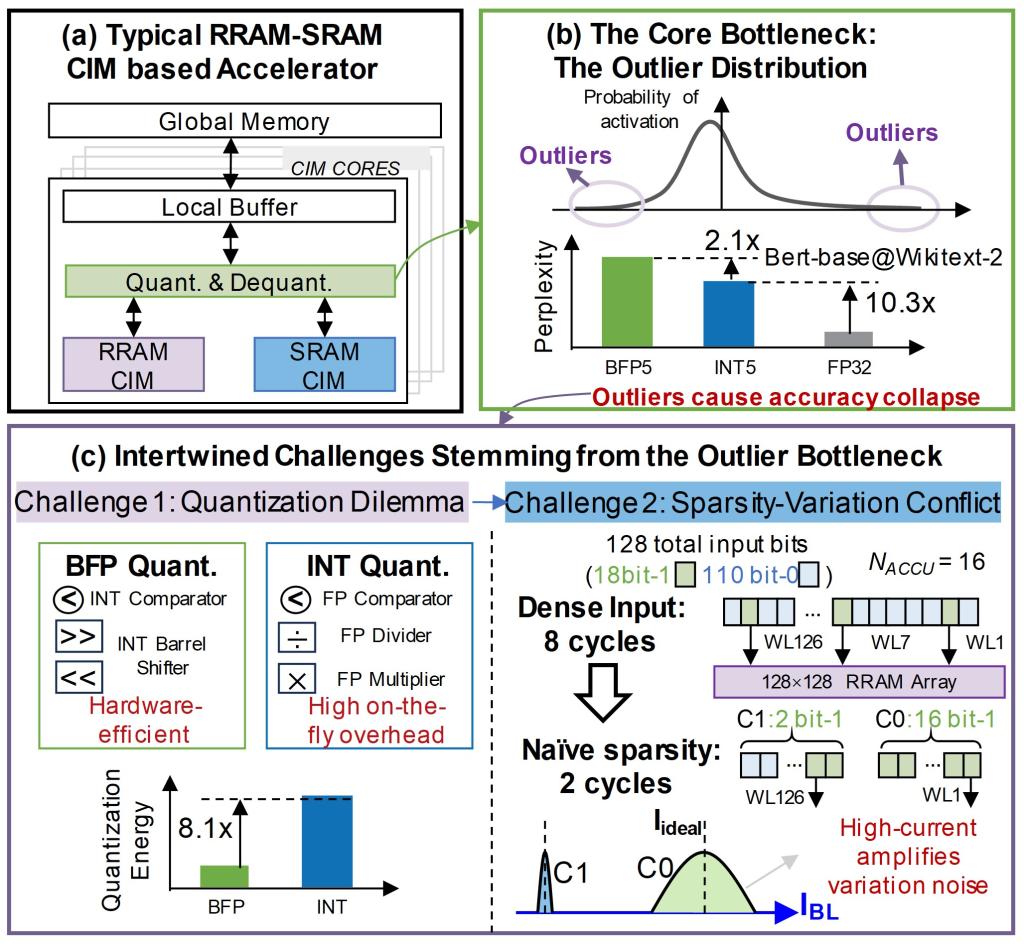
图2 (a)典型RRAM-SRAM存算加速器;(b)异常值是Transformer量化的核心瓶颈;(c)量化困境和稀疏-噪声矛盾。
针对上述难题,团队通过软硬协同设计实现了突破。在算法层面,团队创新性地提出了离群值感知块浮点量化框架,通过引入双共享指数分别处理离群值和小数值,在5-bit低位宽下实现了接近FP32的高精度,有效解决了传统块浮点量化在离群值面前的精度崩塌问题。在硬件层面,设计了平衡位稀疏调度机制,不同于传统的“直接跳零”,该机制能动态平衡负载,在降低功耗的同时抑制了电流尖峰引起的噪声,显著增强了模拟计算的鲁棒性
基于32nm工艺的评估展示,OAH-CIM在ImageNet和GLUE基准测试中均大幅超过5-bit整型和块浮点量化,同时对于器件噪声更具鲁棒性。峰值能效高达8.6 TOPS/W,相比当前先进的RRAM存算加速器实现了2.3倍的能效提升,为边缘端高效部署Transformer提供了新范式。
成果二:高效存内搜索引擎
论文题目:“MemSearch: An Efficient Memristive In-memory Search Engine with Configurable Similarity Measures”,集成电路学院博士生余颖洁为第一作者。

图3 余颖洁演讲照片
随着大语言模型(LLM)与检索增强生成(RAG)技术的爆发,通用向量数据库(Vector Database)已成为人工智能的核心。然而,如何在海量的高维向量数据中,快速、低功耗地找到“最近邻(Nearest Neighbor)”,已成为制约系统响应速度的核心痛点。传统的冯·诺依曼架构面临严峻的“存储墙”瓶颈,数据搬运消耗了大量能效。而现有的存算一体方案虽然能加速矩阵乘法,却面临一个“通用性难题”:大多数存算硬件仅支持简单的点积(Dot Product)运算,难以高效支持工业界广泛应用的欧式距离(L2)和余弦相似度(Cosine)——后两者涉及平方、开方及除法等复杂非线性运算,通常需要昂贵的数字电路辅助,严重削弱了存算一体的能效优势。
针对这一挑战,团队提出了“MemSearch”——一款基于忆阻器的高效存算一体搜索引擎,实现了算法与硬件的高效协同(图4)。该研究通过以下核心创新,解决了向量搜索中多度量标准兼容与能效低下的难题:
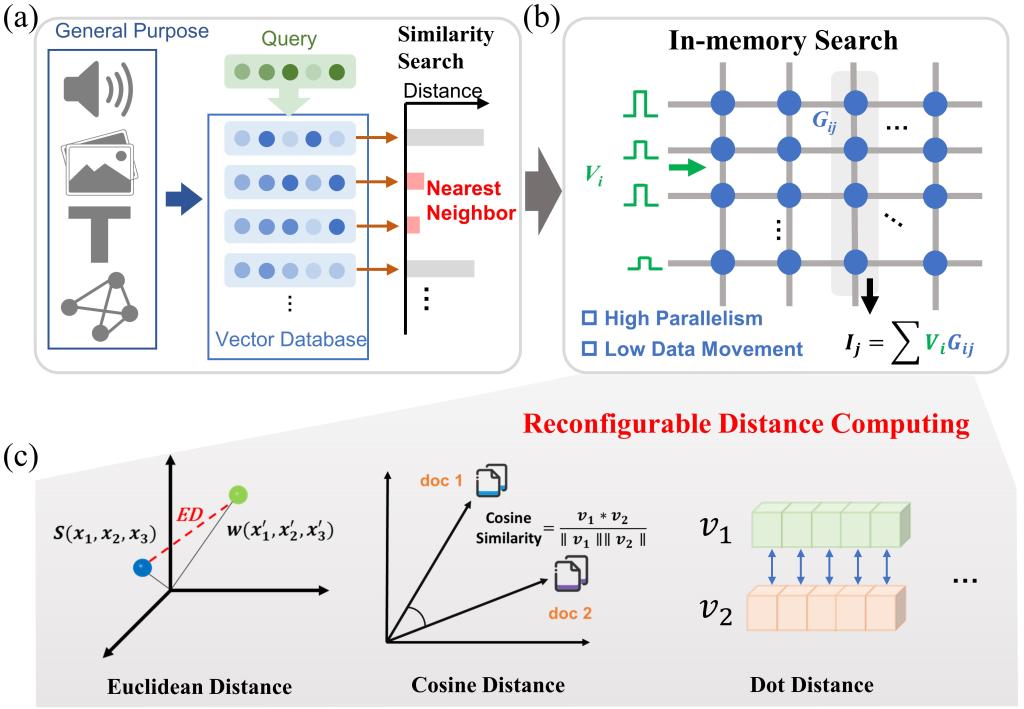
图4 (a)在通用向量数据库中执行相似度搜索(b)存内搜索的原理(c)不同形式的距离计算
(1)数据存储层面:提出了统一相似性元素映射方案,该方案不仅能存储向量本身,还能同步处理向量模长等关键信息,首次在忆阻器阵列上实现了对点积、欧式距离和余弦距离等多种距离计算公式的通用兼容。
(2)计算架构层面:设计了一款专用的可重构模拟电流计算电路。该电路能够根据不同搜索需求,动态执行加法、乘法、除法以及平方等多种运算。实验显示,电路在执行复杂计算时仅增加极低的能耗(欧式距离仅4.4%,余弦距离仅9.9%),却换来了硬件配置的灵活性。
(3)针对工业界至关重要的有符号定点数运算,MemSearch 引入了符号阵列与数值阵列的解耦设计,完美支持了大模型等应用中常见的高精度有符号向量搜索,填补了以往存算一体方案在通用性上的空白 。
团队基于65nm工艺对MemSearch进行了全流程评估。实验结果表明,在处理图像、语音、文本等多种模态的数据集时,MemSearch在保持极低精度损失的前提下,展现了显著的能效优势。相比于传统数字处理器,在其执行点乘距离、欧式距离、余弦距离搜索时,能效分别提升了864倍、802倍、1474倍。该工作展示了忆阻器在构建未来高效通用型存算一体向量数据库方面的巨大潜力,为大规模人工智能检索、推荐系统及大语言模型的高效部署开辟了全新的硬件路径。
上述两篇论文的通讯作者均为李祎教授和缪向水教授,华中科技大学集成电路学院为论文的第一完成单位。合作者还包括香港科技大学李健聪博士后及香港智能晶片研究中心陈佳博士。
本研究工作得到了国家科技创新2030重大研究项目、国家重点研发计划、国家高层次青年人才计划、湖北省自然科学基金杰出青年项目等资助,以及国家集成电路产教融合创新平台、先进存储器湖北省重点实验室的支持。









